

この記事を書いた人
・AI×ブログ運営に挑戦中!
・ ChatGPT・生成AIで記事作成を研究
・ブログの効率化&収益化を発信!
「AI×ブログ」の可能性を探求し、学びをシェア!
Stable Diffusionといえば「テキストを入力するだけで画像が生成できるAI」として話題ですが、実はそれだけではありません。
特定の人物やスタイルを学習させて、オリジナルの画像を生成することも可能です。
この記事では、それぞれの特徴や使い方を初心者でもわかりやすく解説します。
2025年最新のツール・環境に対応した情報なので、これから始める人にも安心です。
目次
1. Stable Diffusionに写真を学習させるとは?
Stable Diffusionはもともと汎用性の高い画像生成モデルですが、LoRAやDreamBoothを使うことで、自分だけのAIモデルを作ることができます。
たとえばこんな活用ができます
- 自分の顔写真を学習させて「アニメ風自画像」を生成
- 特定のアーティストの画風を学習させて、似た雰囲気の作品を作る
- ペットの写真を取り込んで、記念イラストを自動生成
- 商品写真を元にしたプロモーション素材の自動作成
このように、個別のスタイルや被写体に最適化されたAIモデルを作ることで、既存の画像生成AIよりも、格段に表現力の高い結果を得られます。
2. LoRAとDreamBoothの違いと選び方
| 手法 | 特徴 | 向いているケース |
|---|---|---|
| LoRA | 軽量で学習が速く、モデルに追記できる | 画風やスタイルの追加、手軽なカスタム |
| DreamBooth | モデル全体を再学習、再現度が高い | 人物・ブランド・固有スタイルの再現重視 |
選び方のポイント
- 短時間で試したい/複数モデルを同時に使いたい → LoRA
- 被写体の細部まで忠実に再現したい/精度重視 → DreamBooth
初心者はまずLoRAから始めて、より高精度なカスタマイズが必要になったらDreamBoothに移行するのが一般的です。
3. LoRAで写真を学習させる方法(軽量で手軽!)
LoRAは、元のモデルの構造を壊さずに情報を上書き・追加できる学習方法です。
数分〜十数分で学習が完了する軽さが魅力です。
必要な環境
- Stable Diffusion Web UI(AUTOMATIC1111版)
- Python、PyTorch(PC環境)
- LoRAスクリプト(例:kohya-ss)
➤ GitHubページはこちら - 学習用写真:20〜100枚(解像度512px以上推奨)
学習の流れ
- 写真収集・前処理
顔・構図・角度が異なる写真を集め、512px以上にリサイズします。 - キャプション作成
各画像にテキスト説明(例:「a smiling man with glasses outdoors」)を付けることで、学習精度が向上します。 - 学習スクリプト実行
kohya-ssを用いてエポック数10〜30回で学習します。VRAMが6GB以上あれば問題ありません。 - LoRAファイル出力&使用
.safetensors形式で保存されるので、Web UIのlora:タグで読み込んで生成に使えます。
活用のヒント
- 他のLoRAファイルと併用可能(例:人物+背景スタイル)
- LoRAはStable Diffusion 1.5と相性が良い
- 軽量なため、ローカルでも快適に動作
4. DreamBoothで写真を学習させる方法(高精度)
DreamBoothは、画像生成モデルを丸ごと再学習し、高精度で被写体を再現することができる強力な手法です。
必要なもの
- Google Colab(無料で使用可)
- Hugging Faceのアカウント(トークン発行)
- 写真データ(20〜50枚)
- DreamBoothノートブック
➤ DreamBooth入門はこちら
手順
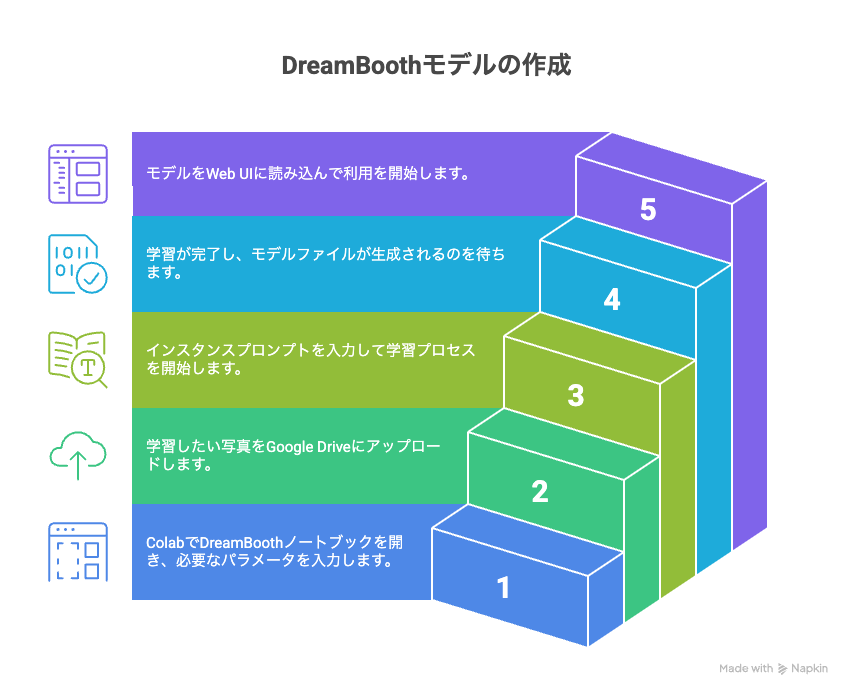
- Colab上でDreamBoothのノートブックを開き、必要なパラメータを入力。
- 学習したい写真をGoogle Driveにアップロード。
- インスタンスプロンプト(例:「a photo of sks person」)を入力し、学習を開始。
- 約1〜2時間で学習が完了し、モデルファイルが生成されます。
- Web UIにモデルを読み込んで利用開始!
活用のヒント
- 肖像画のようなクオリティで再現可能
- ブランドロゴや商品スタイルを学習させる事例も多数
- 難点はファイルサイズが大きく、共有しにくいこと
5. 学習データの選び方と注意点
良い学習写真の特徴
- 被写体が明確(特に顔がはっきり写っている)
- シンプルな背景(ノイズを減らす)
- 表情・角度・衣装のバリエーションが豊富
NGな例
- ピンボケや背景がうるさい写真
- 著作権のある写真や、本人の同意がない人物画像
- 学習データが少なすぎる(精度が極端に下がる)
6. まとめ|まずはLoRAで始めよう!
- LoRA:軽量・高速・複数のカスタム要素と組み合わせ可能
- DreamBooth:高精度・人物やスタイルの忠実な再現に最適
初心者でも扱いやすいのはLoRA。短時間で結果が見えるため、画像生成AIに慣れる第一歩としてぴったりです。
精度を求める場面ではDreamBoothが活躍しますが、使用には多少の環境構築と時間が必要なので、段階的に学ぶのがおすすめです。

{kind=link}